Sparkscan
Real-time block explorer with streaming data pipeline
GoRustTypeScriptKafkaRisingWaveClickHousePostgreSQLAWS EKS
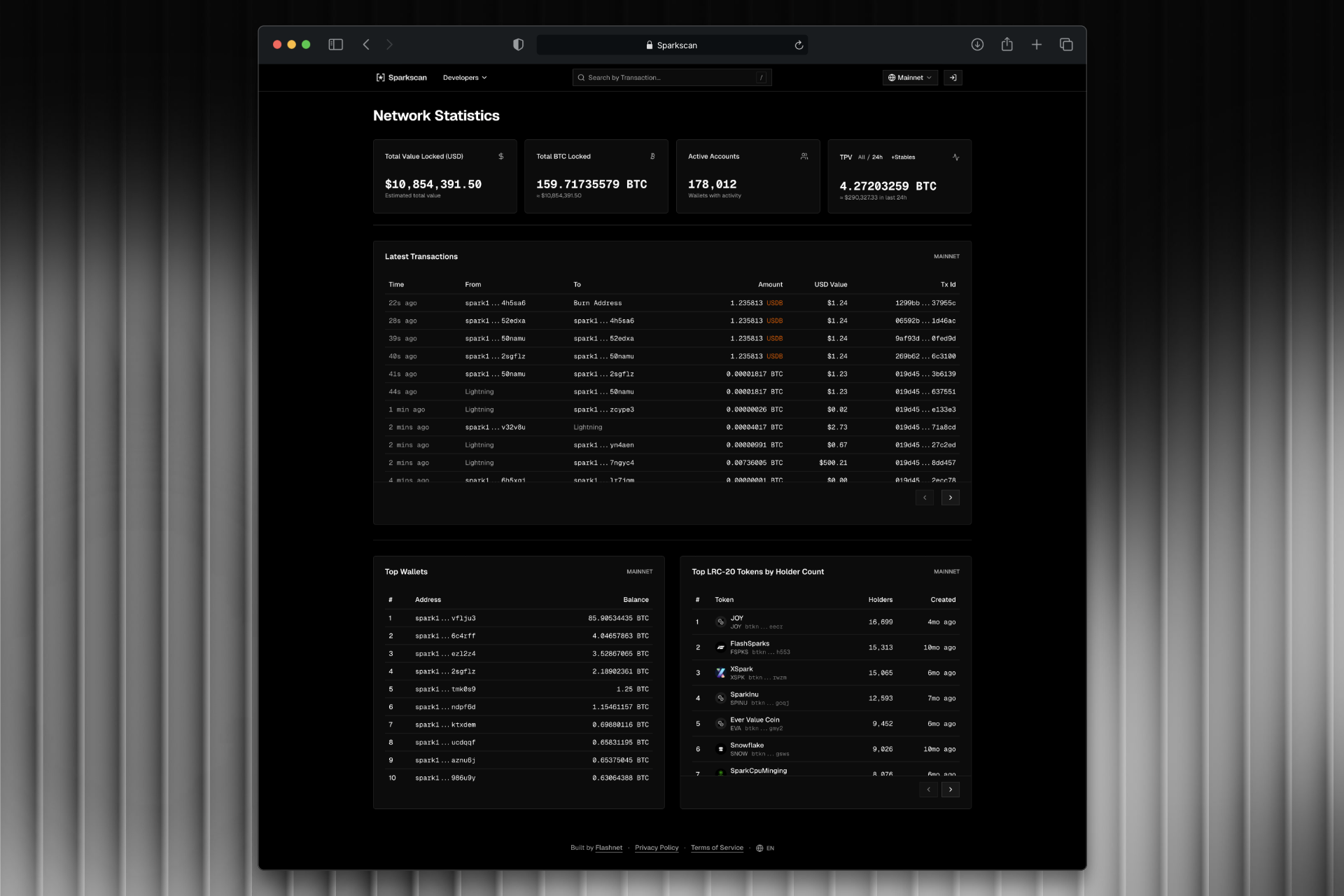
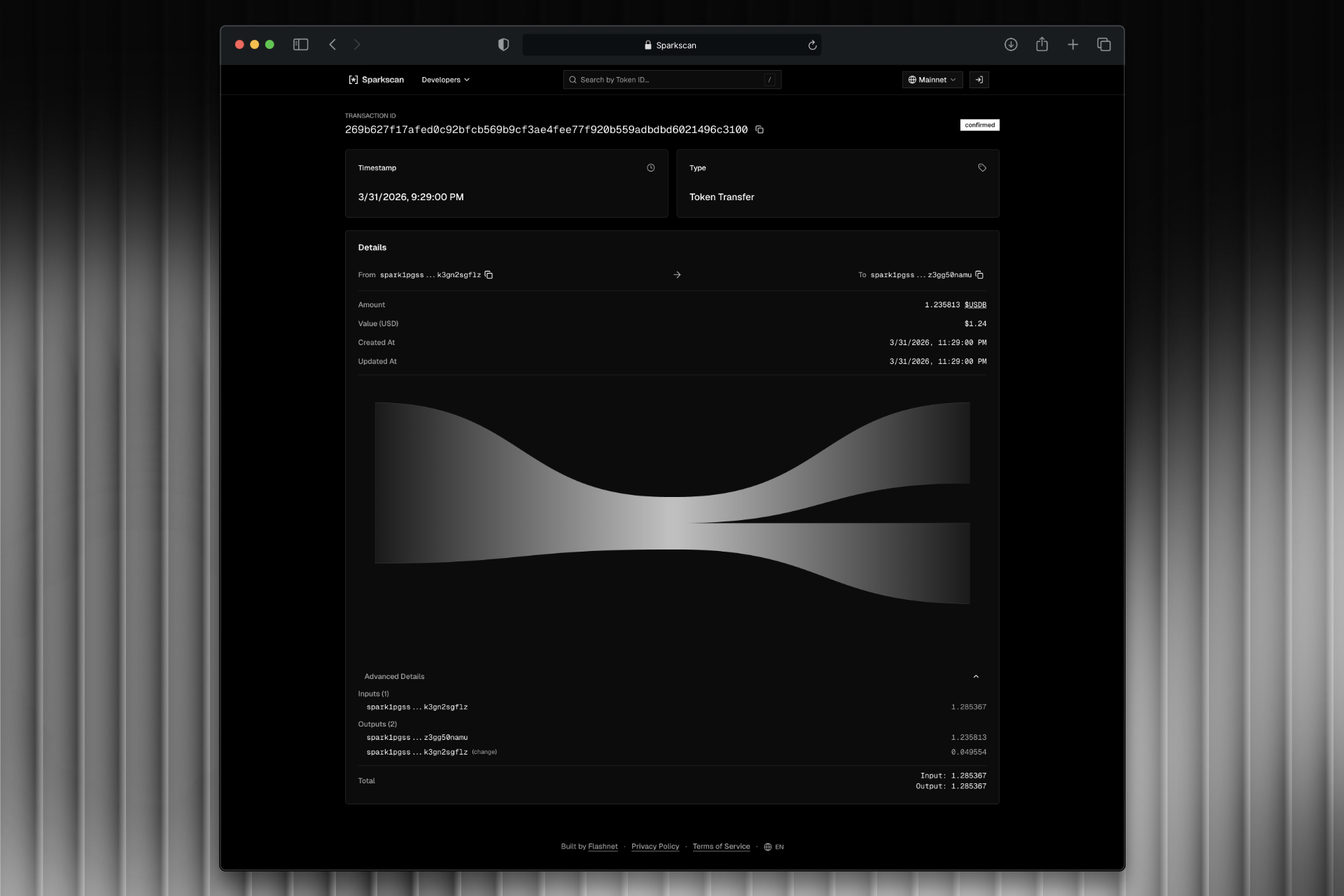
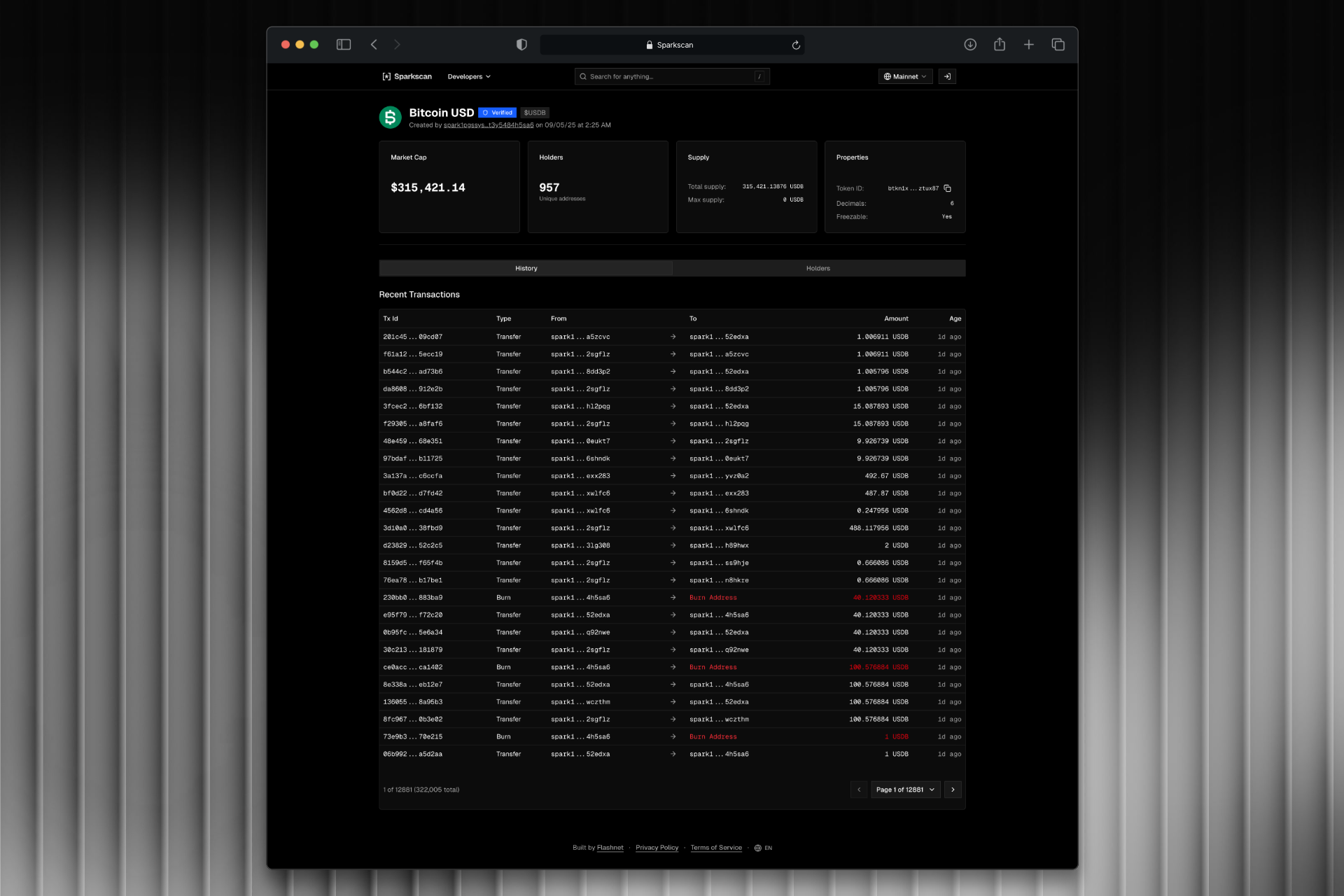
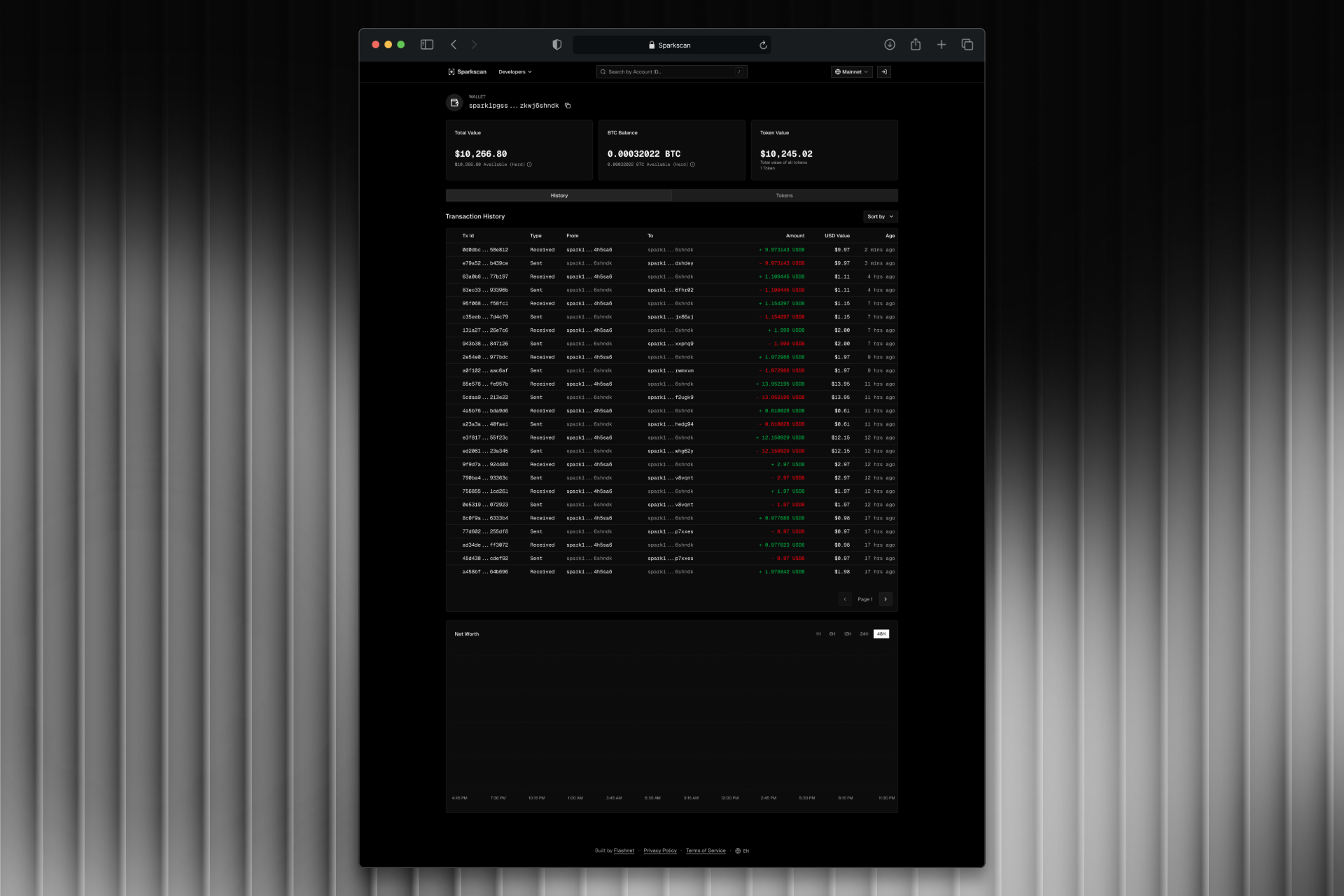
Block explorer and data engine for the Spark blockchain. Built a streaming pipeline from Kafka through RisingWave to ClickHouse, with a REST API serving geospatial analytics and chain data.